
ControlNet Is The Next Big Thing In AI Images
This is the bleeding edge of consumer grade AI imagery

ControlNet helps artists and creators make images from written descriptions. This new version, ControlNet 1.1, gives creators even more ways to customize and control how the images are made. It works with a tool called Automatic1111, which we’ve covered how to install, and opens up many new creative possibilities for making unique and stunning images. In this article, we explore the different features and use cases for each specific ControlNet model via a free HuggingFace web environment.
Link To No Code AI Image Generation Here
I must warn you that these techniques are brand new, and won’t often make the exact image you think of in your head.
It’s wise to stay curious and roll with the punches. Just try a bunch of things a bunch of times in an effort to learn how to get the images you picture in your head.
But why spend so much time on AI if it doesn’t always give you what you want?
The AI space moves so fast, it seems a groundbreaking technique comes out once a month. Every time that happens, there are a few short weeks where everybody has a level playing field because nobody’s used this brand-new technique before. In these short few weeks of tinkering, there’s space for you to be one of the pioneers of a novel concept. And novel things get more attention than non-novel things. More attention can be used as leverage in your personal and business life. However, every time a new technique comes out there’s a group of people that were experimenting with it every single time. As time goes on, that level playing field starts to become out of reach for those that haven’t experimented with it at all.
Features in ControlNet 1.1 And When To Use Them
ControlNet has a handful of models that give you control over your composition as you’ve never seen in AI imagery. I like to think of this toolset as a way to reskin a preexisting composition, character, pose, or text image.
I’ve included pictures for each feature to clearly showcase what it does. I encourage you to think about how you as a human could use these features in your personal and professional life.
Tip: If you get an error while using one of these tools, try another picture that better aligns with the best use of the feature outlined in this blog
ControlNet Canny Edge
Canny Edge is ideal for tasks that require clear boundaries, such as illustrations and cartoons.
Just upload a picture & input a text prompt. ControlNet will ‘preprocess’ the image, turning it into a Canny Edge image, then use the outline to inform the generated image.
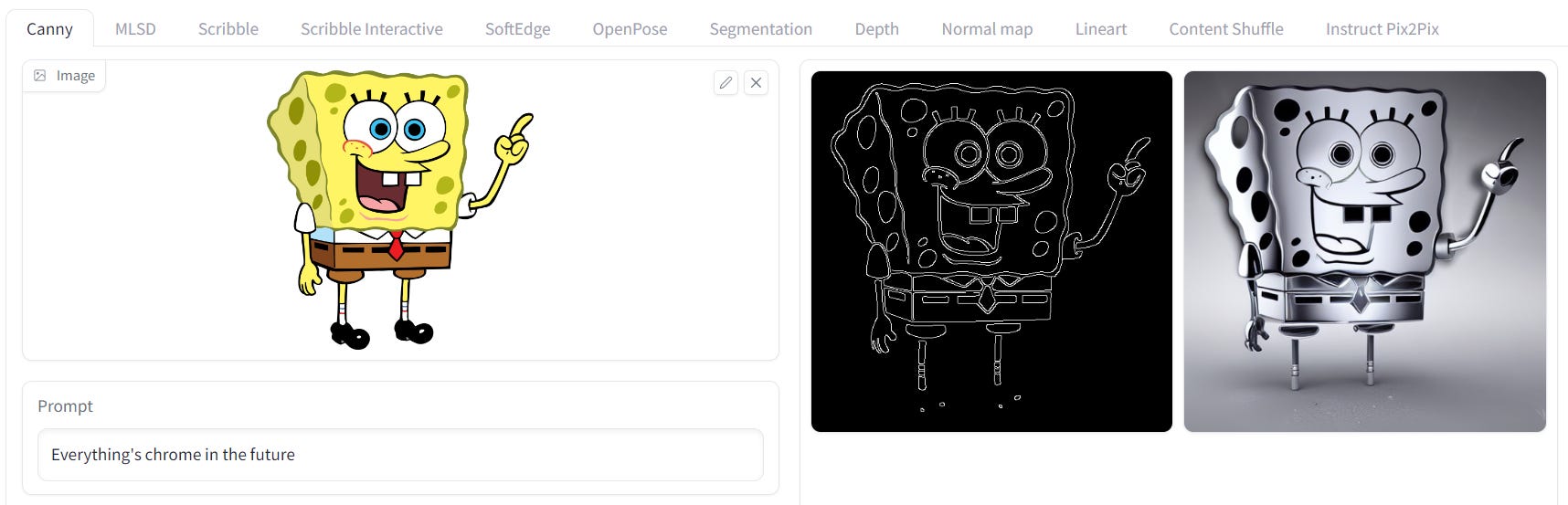
I will say that outputs generated on your first go probably won’t be breathtaking. I encourage you to experiment with your text prompts first, then try going in to advanced settings and messing with canny low/high threshold & the guidance weight.
ControlNet with M-LSD Lines
By utilizing M-LSD (Mobile Line Segment Detector) straight line detection, this model effectively generates images with geometrically defined structures, such as rooms and buildings.
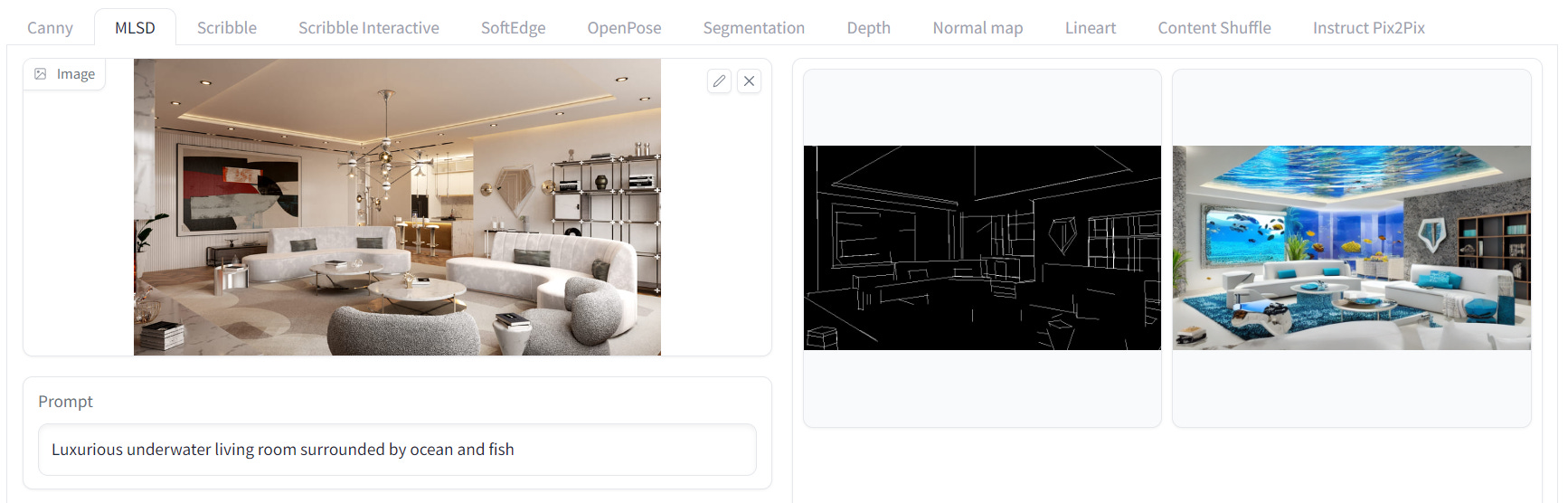
As seen above, we reskinned a modern living room to an underwater living room. I can see this method being great for storyboarding and concepting any interior and exterior scene you need.
ControlNet with Scribble
Scribble allows users to guide the image generation process by providing hand-drawn scribbles as inputs. These scribbles serve as visual cues or hints for the model, specifying color regions, patterns, or specific structures within the image. With scribble, users can exert creative control over the generated image, influencing its appearance and content to align with their artistic vision.
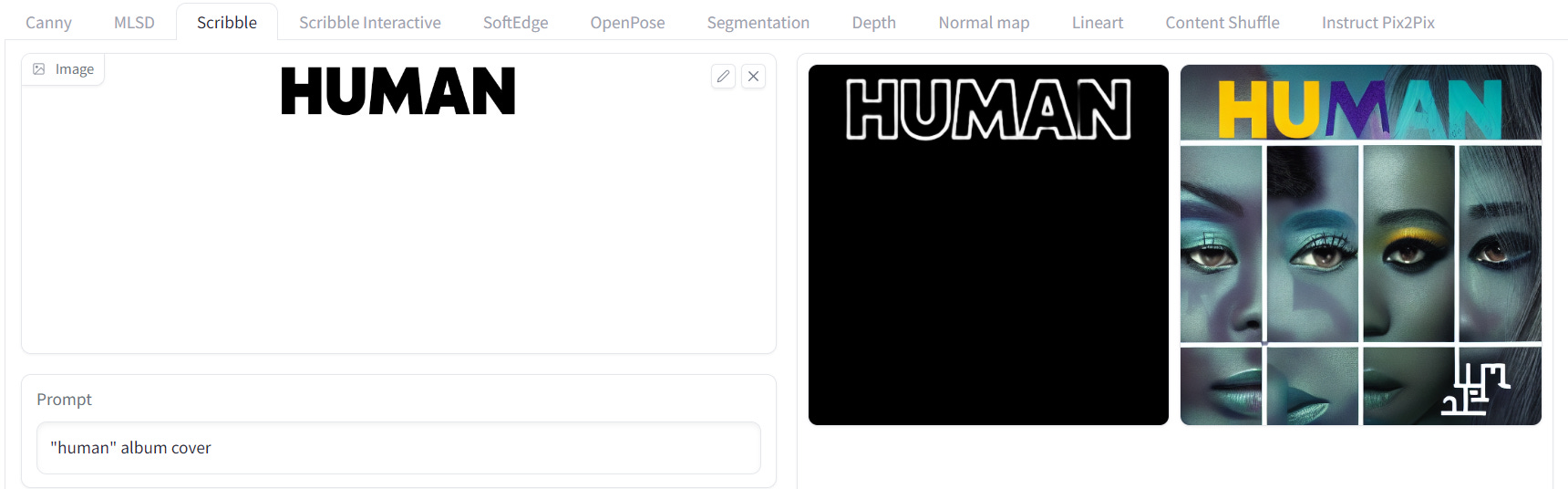
I’m a big fan of Scribble and often give it images with typography to get cohesive words from an AI output.
ControlNet with Scribble Interactive
This one is the exact same as Scribble, but the user can write their own scribble.
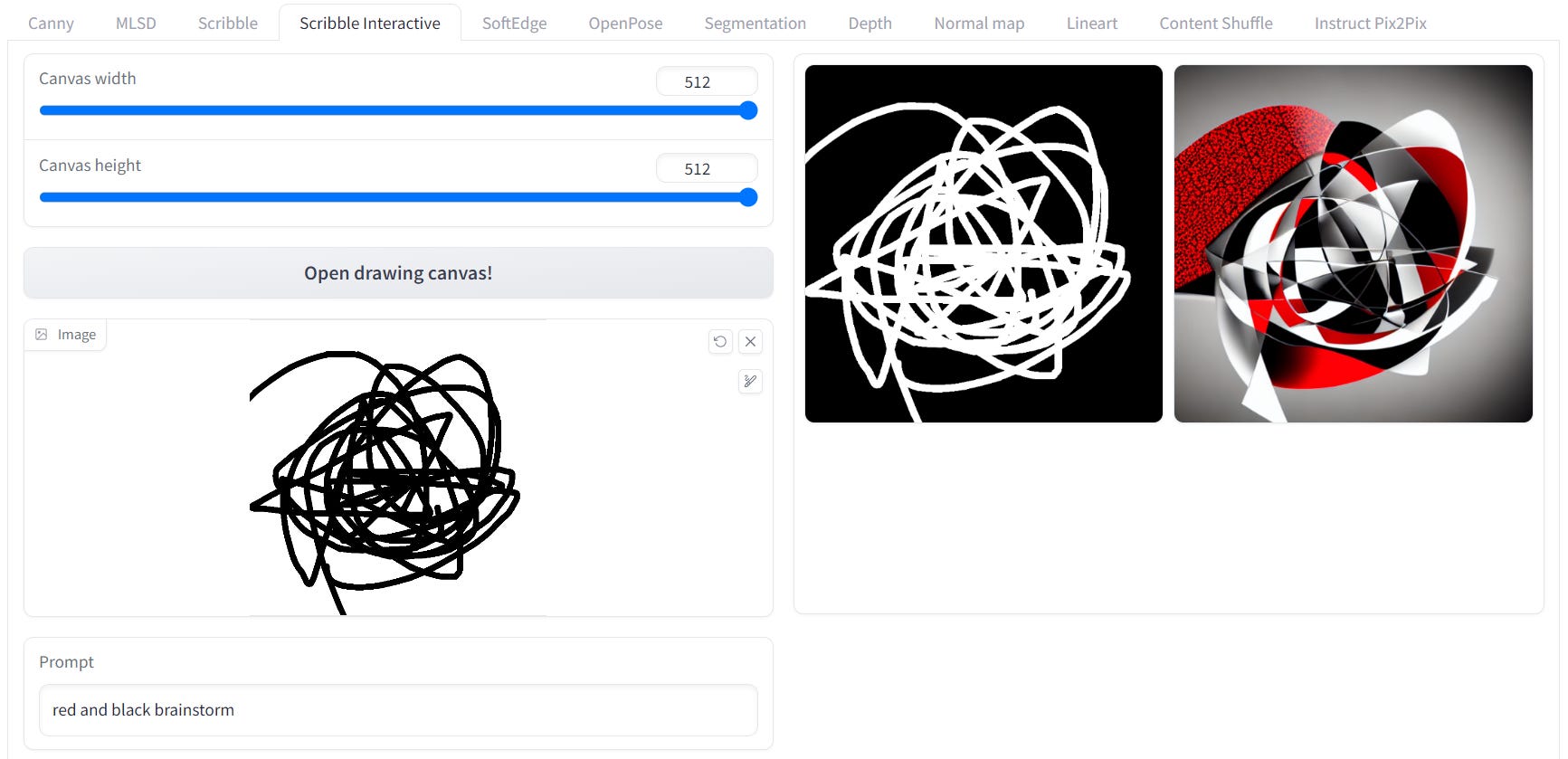
ControlNet with SoftEdge
ControlNet's integration with soft HED (Holistically-Nested Edge Detection) Boundary allows the preservation of details in input images, making it suitable for recoloring, remixing, and stylizing images.

ControlNet with OpenPose
This model allows users to generate images with specific body postures. It is perfect for generating images of characters in different scenes, such as a chef in a kitchen or an astronaut on the moon.
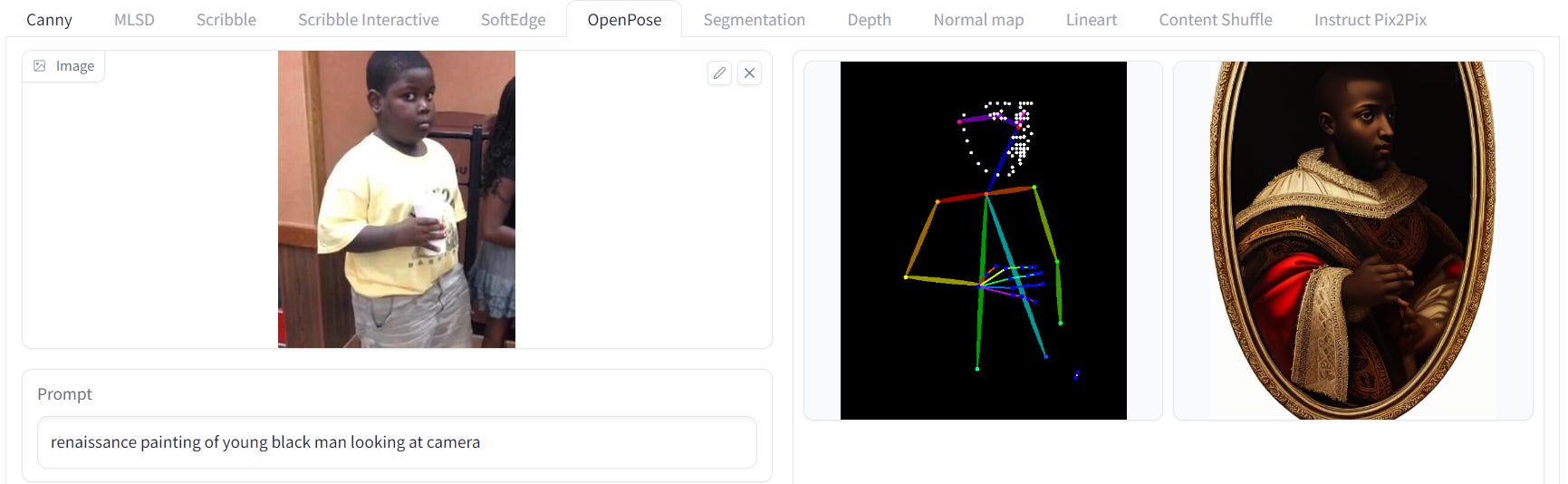
This is one of my favorite concepts, although I’ve found it difficult to get a result with no AI jankiness. In a year or two, this method will be very practical.
ControlNet with Semantic Segmentation
Segmentation is used to split the image into "chunks" of more or less related elements ("semantic segmentation"). All fine detail and depth from the original image is lost, but the shapes of each chunk will remain more or less consistent for every image generation. It is ideal for, but not limited to, generating images of landscapes and nature.
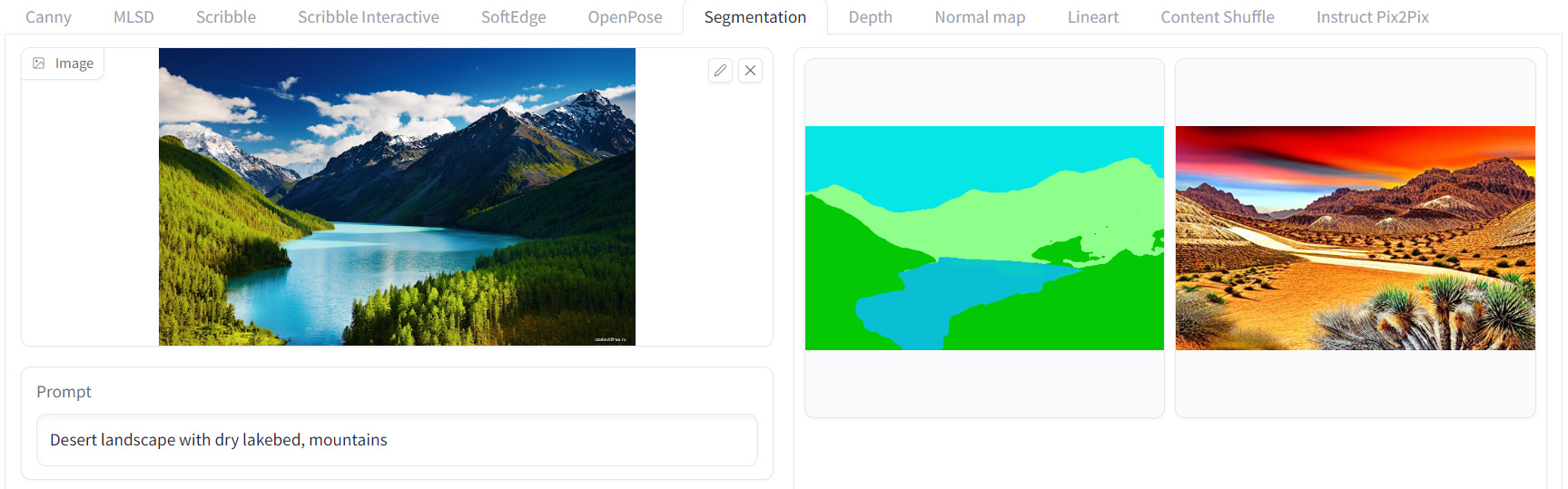
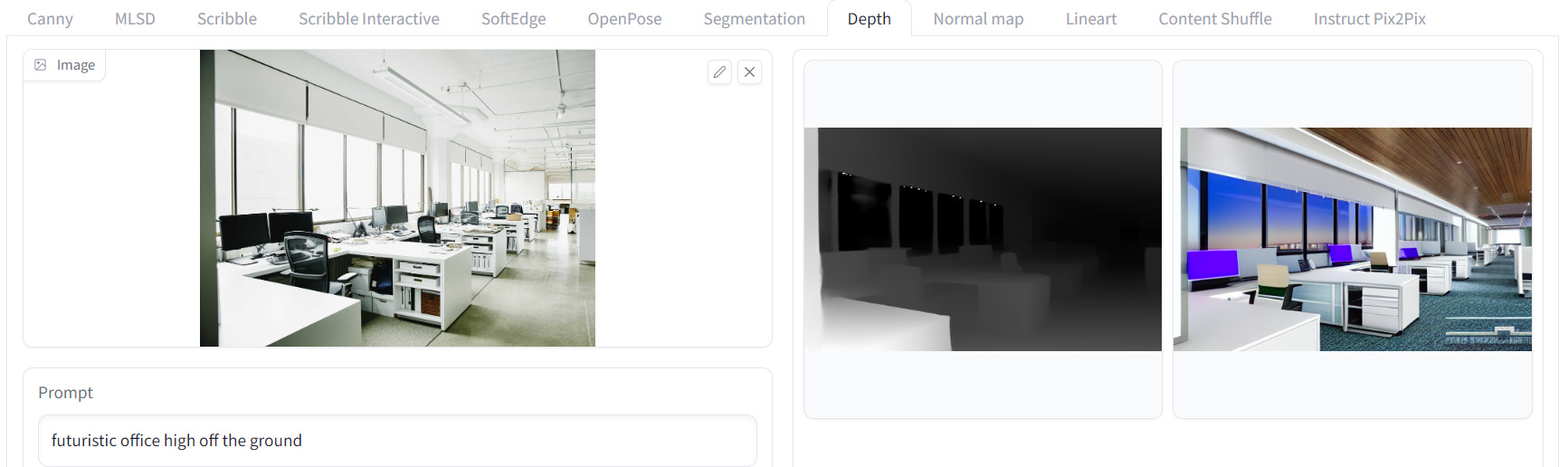
ControlNet with Depth
A depth map is an image or image channel that contains information relating to the distance of the surfaces of scene objects from a viewpoint. It provides creative freedom for generating images with different depth perspectives. It can also be used to inform an artistic image with a blurry background.
See you next Monday at 7 am EST :)
The Bleeding Edge is a weekly newsletter revolving around using cutting-edge technology to improve your life, productivity, business, or well-being. If you are not already a subscriber, sign up and join 200+ others who receive it directly in their inbox each week.